PROTOCOLO HTTP
El Protocolo de Transferencia de Hipertexto (HTTP, por sus siglas en unglés, Hypertext Transfer Protocol) es un protocolo de comunicación utilizado para la transferencia de datos en las World Wide Web (WWW). Fue desarrollado para permitir la comunicacipon entre clientes (como navegadores web) y servidores web. HTTO es un protocolo de la capa de aplicación en el modelo OSI y se utiliza para solicitar y transmitir recursos, como documentos HTML, imágenes, videos y otros tipos de datos, entre un cliente y un servidor a través de internet.
Estructura y funcionamiento
El HTTP tiene una estructura y funcionamiento relativamente sencillos. A continuación, te proporciono una descripción de cómo funciona HTTP y su estructura básica:
-
Línea de solicitud (Request Line): Esta línea contiene tres elementos clavé: el método HTTP,
la URL (Uniforme Resource Locator)del recurso solicitado y versión de HTTP que se está utilizando.
-
Encabezados (Headers): Los encabezados proporcionan información adicional sobre la solicitud
y el cliente. Pueden incluir encavezados de solicitud estádar, como "User-Agent" (identifica el navegador
o el cliente), "Host" (el nombre del servidor), "Accept" (tipos de medios que el cliente acepta), entre
otros. Los encabezados también pueden ser personalizados.
-
Cuerpo de una solicitud(Body): El cuerpo de la solicitud es opcional y generalmente se
usa para enviar datos adicionales al servidor, como en formularios werb, Por ejemplo, cuando
completas un formulario en línea y haces clic en "Enviar", los datos del formulario se incluyen
en el cuerpo de la solicitud.
Funcionamiento de protocolo
EL funcionamiento de HTTP se basa en el modelo cliente-servidor, donde un cliente (como un navegador web) realiza solicitudes a un servidor web para obtener recursos, y el servidor responde con esos recuros. Aquí hay un resumen del proceso:
-
El cliente inicia una conexión con el sercidor web utilizando el protocolo TCP (o TLS para
conexiones seguras).
-
El cliente envía una solicitud HTTP al sercidor, que incluye la línea solicitud, los
encabezados y, opcionalmente, el cuerpo de la solicitud.
-
El servidor recibe la solicitud, procesa la solicitud y determina si puede satisfacerla. Si puede,
genera una respuesta HTTP que incluye la línea de estado, los encabezados y el cuerpo de la respuesta.
-
El servidor envía la respuesta al cliente a través de la misma conexión establecida anteriormente.
-
El cliente recibe la respuesta, procesa el contenido (por ejemplo, renderiza una página web si la
respuesta es HTML) y muestra los resultados al usuario.
-
Si es necesario, se puede realizar solicitudes adicionales entre el cliente y el servidor para
cargar recueross adicionales (como imágenes, hojas de estilo, scrips, etc.) para completar la página web.
Este proceso de solicitud y respuesta se repite continuamente mientras el usuario interactúa con un sitio web, lo que permite la navegación y la obtención de recursos en la web. La versión específica de HTTP utilizada y la forma en que se maneja las conexiones pueden variar según la implementación y la configuración del servidor y el cliente.
>Metodos de petición
-
HTTP define varios métodos de solicitud que indican la acción que se debe realizar en un recurso identificado
por una URL. Estos métodos se utilizan para realizar operaciones específicasa en un servidor web. Aquí tienes
una descripción de los métodos de petición HTTP más comunes:
-
GET: El método GET se utiliza para socializar datos de un recurso en el servidor. Cuando un cliente envía
una solicitud GET, está pidiendo al servidor que envíe una copia del recurso especificado en la URL de la solicitud.
Este método es seguro y no debe tener un impacto en el estado del servidor ni en los datos del recurso.
-
POST: El método POST se utiliza para enviar datos al servidor para su procesamiento. La solicitud POST
generalmente incluye datos en el cuerpo de la solicitud, que pueden ser formularios HTML, datos JSON o cualquier otro tipo
de información. Este método se utiliza para crear nuevos recursos en el servidor o para realizar modificaciones en recursos
en el servidor o para realizr modificaciones en recursos existentes. No es seguro y puede cambiar el estado del servidor.
-
PUT: El método PUT se utiliza para actualizar un recurso en el servidor o para crearlo si no existe. Al igual
que POST, PUT también envía datos en el cuerpo de la solicitud, pero a diferencia de POST, se espera que significa que realizar
la misma solicitud varias veces no debería tener un efecto diferente al de una sola solicitud. PUT se usa para reemplazar
completamente el recurso existente en la URL especificada.
-
DELETE: El método DELETE se utiliza para eliminar un recuros en el servidor identificado por la URL
de la solicitud
-
PATCH:El método PATCH se utiliza para aplicar modificaciones parciales a un recurso en el servidor. A diferencia de PUT,
que reemplaza completamente el recuros, PATCH se utiliza para realizar actualizaciones para parciales o increementales en el recurso
existe. El cuerpo de la solicitud PATCH contiene las modificaciones que se deben aplicar al recurso.
-
HEAD: El método HEAD es similar GET, pero el sercidor solo responde con los encavezados de la respuestay sin el cuerpo
del recurso. Se utiliza para obtener información sobre el recurso, como encabezados, sin descargar realmente el contenido ocmpleto,
lo que puede ser útil para verificar la existencia o la fecha de modificación de un recurso.
-
OPTIONS:El método OPTIONS se utiliza para solicitar información sobre las opciones de comunicación disponibles para recursos.
El sercidor responde con una lista de métodos de solicitud permitidos, encabezados admitidos y otras capacidades relacionadas con el recurso.
-
CONNECT:El método CONNECT se utiliza paraestavlecer una coneción dered con un recurso, generalmente a través de un proxy. Es utilizado
para establecer una conexión de red con un recurso, generalmente a través de un proxy. Es utilizado para establecer un túnel SSL (Secure Sockets
Layer) a través de un proxy.
-
TRACE: El método TRACE se utiliza para realizar un seguimiento de la ruta que toma la solicid a través de servidores
y proxies. Esta solicid se utiliza principalmente para diagnósticos y depuración.
Cada método de solicitud tiene un propósito específico y debe utilizarse de acuerdo con las conversaciones y estándares de HTTP. Los servidores web pueden admitir diferentes combinaciones de estos métodos según su configuración y la aplicación que alojan.
METODOS DE RESPUESTA
HTTP define códigos de estado de respuesta que indican el resultado de una solicitud realizada por un cliente a un servidor web. Estos códigos de estado se incluyen en la línea de estado de una respuesta HTTP y proporcionana información sobre el éxito o el fracaso de la solicitud. A continuación, se presentan algunos de los códigos de estado de respuesta HTTP más comunes:
-
200 OK: Indica que la solicitud ha sido exitosa y que el servidor ha respondido con el recuros solicitado.
Es el código de estado estándar para respuestas exitosas.
-
201 Created: Se utiliza para indicar que la solicitud ha tenido éxito y que como resultado se ha creado
un nuevo recurso en el servidor. Por lo general, se utiliza en respuesta a solicitudes POST o PUT.
-
204 No Content: Indica que la solicitud se ha completado correctamente, pero no hay contenido para devolver en la respuesta. Se utiliza,
ejemplo, cuando se ha realizado una solicitud DELETE exitosa.
-
400 Bad Request: Se utiliza para indicar que la solicitud del cliente es incorrecta o está mal fomasa de alguna manera. El servidor no puede
comprender o precesar la solicitud devido a errores en los datos enviados por elcliente.
-
401Unauthorized: Inidica que la solicitud requiere autenticación y el cliente no ha proporcionado credenciales válidas o no está autorizado para acceder
al recurso.
-
Forbidden: Se utiliza para indicar que el servidor comprende la solicitud, pero el acceso al recuros solicitado está prohibido para el cliente. Esto puede degerse
a falta de permisos o restricciones de seguridad.
-
404 Not Found: Indica que el recuro solicitado no se encuentra en el servidor. Es uno de los códigos de estado más comunes
cuando una URL no existe o es incorrecta.
-
500 Internal Server Error: Indica que se ha producido un error interno en el servidor al procesar la solicitud. Este código de estado generalmente
inidica un problema en el servidor.
-
502 Bad Getaway: Inidica que el servidor actuó como internmedio o proxy y recivío una respuesta no válidas
o nula del servidor al que estaba reenviando la solicitud.
-
503 Service Uniavailable: Indica que el servidor no puede procesar la solicitud en este momento debido a una sobrecargo mantenimiento. El cliente puede
intentar la solicitud más tarde.
-
504 Gateway Timeout: Similar a 502, indica que el servidor intermediario o proxy no recivío una respuesta oportuna del servidor al que estaba reenviando
la solicitud.
Estos son solo algunos ejemplos de código de estado de respuesta HTTP. Existen otros códigos que se utilizan para casos más específicos y detallados. Los códigos de estado son una parte fundamental de la comunicación HTTP, ya que proporcionan información crucial sobre el resultado de una solicitud y permiten a los clientes y servidores web tomar medidas apropiadas en funcióne de esa información.
PUERTOS DE RED
Los puertos de red TCP(Transmission Control Protocol) y UDP (User Datafram Protocol) son dos protocolos de transporte que se utilizan en las comunicaciones de redes de computadoras para facilitar la transferencia de datos entre dispositivos. Estos protocolos se utilizan en conjunto con las direcciones IP para dirigir el tráfico de red al destino correcto.
TCP (Transmission Control Protocol):
-
Fiabilidad:TCP es un protocolo orientado a la conexión y garantiza la entrega confiable
de datos. Esto significa que cuando envías datos a través de TCP, se establece una conexión
entre el remitentey el receptor, y se cerifica que los datos se entreguen en el orden correcto
y sin errores.
-
Control de flujo: TCP controla el flujo de datos para evitar la congestión en la red.
Ajusta automáticamente la velocidad de transmisión para garantizar un rendimiento óptimo.
-
Orientado a streams: Los datos se transmiten como un flujo continuo, y TCP se encarga de
dividirlos en segmentos y reensamblarlos en el orden correcto en el extremo receptor.
-
Uso común:TCP se utiliza en aplicaciones donde la integridad de los datos y la secuencia
son críticas, como la transferencia de archivos, el correo electrónico (SMTP, POP3),
la navegación web (HTTP), y muchas otras aplicaciones de comunicación.
UDP (Usuer Datagram Protocol)
-
Menos Confiable: A diferencia de TCP, UDP es un protocolo sin conexión y no garantiza la
entrega de datos ni su orden. Los datos se envían como datagramas individuales, y no se realiza
un seguimiento de si llegan al destino.
-
Velocidad y eficiencia: UDP es más rápido que TCP porque no tiene el sobrecosto de
establecer y mantener una conexión. Es útil para aplicaciones donde la velocidad es más
importante que la confiabilidad, como videoconferencias, transmisión de video en tiempo real
(por ejemplo, streaming), y juegos en línea.
-
Uso común: UDP se utiliza en aplicaciones donde la pérdida ocasional de datos no es
crítica, y la latencia es un factor importante.
TCP se centra en la confiabilidad y la integridad de los datos, mientras que UDP se enfoca en la velocidad y la eficiencia. La elección entre TCP y UDP depende de las necesidades específicas de la aplicación y de si la prioridad es la entrega garantizada de datos o la velocidad de transmisión.
A continuación, te proporcionaré una lista de los puertos comunes utilizados por algunos de los protocolos:
-
HTTP (Hypertext Transfer Protocol): Puertp TCP 80 (predeterminado).
-
HTTPS (Hypertext Transfer Protocol Secure): Puerto TCP 443 (predeterminado).
-
SMTP (Simple Mail Transfer Protocol): Puerto TCP 25 (predeterminado).
-
POP3 (Post Office Protocol, versión 3): Puerto TCP 110 (oredeterminado).
-
IMAP (Internet Message Access Protocol): Puertp TCP 143 (predeterminado).
-
MIME (Multipurpose Internet Mail Extensions): MIME no utilizada un puerto específico
por sí mismo. Se utiliza en conjunto con los protocolos de correo electrónico, como SMTP, POP3,
y IMAP, que tienen sus propios puertos.
-
FTP (File Transfer Protocol): Puerto TCP 21 (predeterminado) para el control,
Puerto TCP 20 (predeterminado) para la transferencia de datos en modo activo.
-
FTPS (FTP Secure): Puerto TCP 990 (prederminado) para el control en modo implícito.
Puerto TCP 21 (predeterminado) para el control en modo explícito.
-
SFTP (SSH File Transfer Protocol): SFTP se ejecuta sobre SSH (Puerto TCP 22 por defecto).
-
BitTorrent: Bit Torrent utiliza una amplia gama de puertos aleatorios para la transferencia
de datos. No tiene un puerto fijo.
-
eDonkey (eDonkey2000): Puerto TCP 4661 (predeterminado) para la búsqueda de servidores.
TCP 4661 (predeterminado) para la búsqueda de servidores.
-
FastTrack: FastTrack utiliza una variedad de puertos, incluyendo algunos en el rango
1024-65535. No tiene un puerto fijo.
-
IRC (Internet Relay Chat): Puerto TCP 6660-6669 (varios puertos) y otros
(dependiendo del servidor).
-
XMPP (Extensible Messaging and Presence Protocol): Puerto TCP 5222 (predeterminado)
para conexiones no seguras. Puerto TCP 5223 (predeterminado) para conexiones seguras.
-
MTProto (Telegram Messenger Protocol): MTProto es el protocolo de comunicación interno de
Telegram y no utiliza un puerto estándar. Telegram puede usar una variedad de puertos aleatorios
para sus conexiones.
LA CLASIFICACIÓN DEL SOFTWERE
-
La clasificación del softwere es unproceso fundamental en la informática que consiste en agrupar y categorizar
los programas informáticos con vase en diversas características y propiedades.
Esta clasificación es esencial para entener, organizar y gestionar la amplia variedad de softwere disponible
en el mundo digital. Los programas informáticos se pueden clasificar de diversas formas, dependiendo
de los criterios utilizados. Los que se usarán para el siguiente ejemplo serán los siguientes: Softwere de aplicación,
Softwere malisioso, Softwere de sistemas y Softwere de licencias.
Cada una de estás clasificaciones proporciona una visión diferente de las capacidades y características
del softwere, lo que facilita su selección y uso en función de las necesidades individuales o empresariales.
.png)
TIPOLOGÍA DE CONTENIDOS EN INTERNET
-
En Internet, la diversidad de contenidos esasombrosa, desde imágenes y videos hasta textos y aplicacipones
interactivas. Una tipología ayuda a organizarlos en grupos con características comunes. Esta clasificación
es esencial para comprender la dinámica de la era digital y nevegar por la inmensa biblioteca virtual
que es Internet. En la siguientes secciones, exploraremos esta tipología, analizando las diferentes categorías
de contenidos en Internet y sus relevancia en nuestra sociedad conectada.
-
CONTENIDOS MULTIMEDIA:
-
-Incluye imágenes, videos, animaciones y contenido audiovisual en general.
-
-Ejemplos: películas, series de televisión, videos de YouTube, memes, GIFs, imágenes de redes
-
CONTENIDOS ESCRITOS:
-
-Se centra en información textual.
-
-Ejemplos: artículos de noticias, blogs, libros electrónicos, documentos académicos, publicaciones en
redes sociales.
-
CONTENIDO INTERACTIVO:
-
-Requiere participación activa del usuario.
-
-Ejemplos: juegos en línea, aplicaciones web interactivas, foros de discusión, encuestas en línea.
-
CONTENIDO ACADÉMICO Y DE INVESTIGACIÓN:
-
-Contenido relacionado con la educación y la investiagación.
-
-Ejemplos: papers académicos, cursos en línea, bases de datos académicas, tutoriales educativos.
-
CONTENIDO DE ENTRETENIMIENTO:
-
-Dirigido principalmente al entretenimiento y diversión.
-
-Ejemplos: memes, chistes, juegos en línea, contenido humorístico, videos virales.
-
CONTENIDO DE NOTICIAS Y ACTUALIDAD:
-
-Información actual y ecentos relevantes.
-
-Ejemplos: tiendas en línea, catálogos de productos, reseñas de productos.
-
CONTENIDO DE COMERCIO ELECTRÓNICO
-
-Relacionado con la compra y venta en línea.
-
-Ejemplos: tiendas en línea, catálogos de productos, reseñas de productos.
-
CONTENIDO DE REDES SOCIALES:
-
-Contenido generado por usuarios en plataformas de redes sociales.
-
-Ejemplos:publicaciones en Facebook, Twitter, Instagram, TikTok, contenido compartido en redes.
-
CONTENIDO DE ENTRETENIMIENTO EN STRAMING:
-
-Contenido multimedia transmitido en tiempo real.
-
-Ejemplos: servicios de transmisión de video como Netflix, Amazon Prime Video, plataformas
de música en streaming.
-
CONTENIDO DE APRENDIZAJE EN LÍNEA:
-
-Orientado al a educación y el desarrollo de habilidades.
-
-Ejemplos: cursos en línea, tutoriales, recursos educativos.
-
CONTENIDO DE USUARIOS GENERADO POR LA COMUNIDAD:
-
-Creado y compartido por la comunidad de usuarios.
-
-Ejemplos: wikis colaborativas, comunidades de fanáticos, contribuciones
de usuarios en sitios web.
-
CONTENIDO DE ESTILO DE VISA Y VIAJES
-
-Relacionado con consejom experiencias y recomendaciones de viajes y estilo de vida.
-
-Ejemplos: blogs de viajes, sitios de críticas de restaurantes, blogs de moda y belleza.
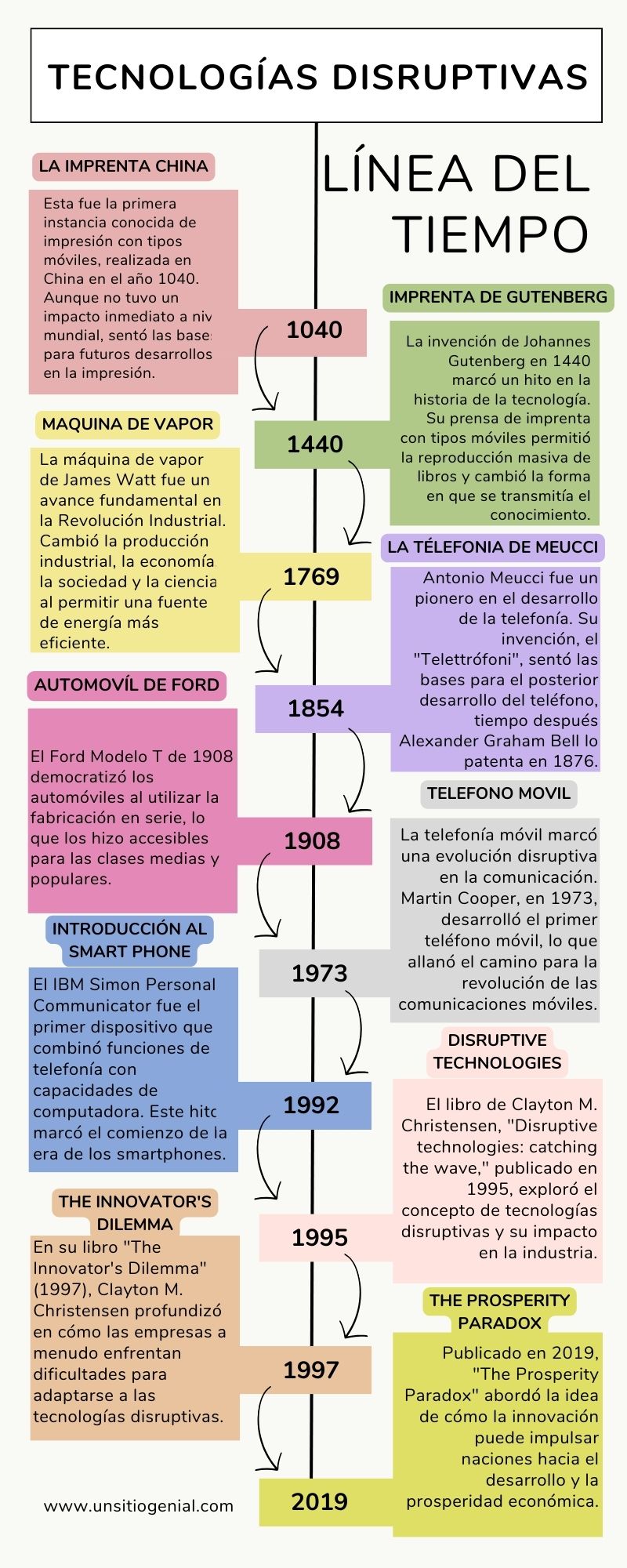
TECNOLOGÍAS DISRUPTIVAS
LPWA

INGENIERÍA DE PROMPT
ESCRIBIR INSTRUCCIONES CLARAS Y ESPECIFICAS:
- Determinar el promp entre comillas o cualquier signo que los separe de las intrucciones.
- Pedir que el OUTPUT sea lo más estructurado posible: Esta táctica es muy util para asegurarse que el modelo sea lo más organizado y estructurado posible
- Pedir si se cumplen las condiciones: Se afirma si el modelo entendió lo solicitado y si generó la respuesta correcta. Al pedir una confirmación explicita, reducimos el riesgo de recibir una respuesta equivocada.
- Ofrecer un ejemplo ayudando a la Inteligencia Artificial a entender qué es lo que estamos esperando de la respuesta; esta táctica nos ayuda con peticiones que pueden tener multiples respuestas o formatos de respuesta.
- Especificar los pasos para terminar una tarea: Si la tarea requiere de barios pasos esto es lo indicado.
- Retroalimentación:
- Resumir:
- Interferencias:
MEJORES PRÁCTICAS PARA LA CREACIÓN DE PROMPTs
- Evaluar los resultados
- Modificar el promt para obtener resultados
- Resumir
- Compendiar
- Crear un extracto
La interferencia es un proceso en el que se utiliza la información disponible para llegar a una conclusión o deducción.
En el contexto de ChatGPT, la inerencia se refiere a la capacidad del modelo para nalizar el texto y extrar información relevante que no está explícitamente presente en el prompt o en las instrucciones dadas.
continuación se presentan unos ejemplos de como utilicé la inteniería en prompt para haccer peticiones a inteligencias artificiales:


Este prompt lo usé para sacar ideas sobre las siguientes peticiones que le haré a las inteligencias artificiales, claro que usé la ingenieria de Prompt

En el siguiente prompt, cometí un error: ya que el decir "documento adjunto" se pensó que subiría un archivo, pero yo solo quería que leyera el texto en parentesis: